SERVICE PHONE
13988889999SERVICE PHONE
13988889999发布时间:2025-11-06 12:50:59 点击量:
哈希游戏,哈希游戏官网,哈希游戏平台,哈希娱乐/哈希游戏作为一种新兴的区块链应用,它巧妙地结合了加密技术与娱乐,为玩家提供了全新的体验。BET哈希平台台凭借其独特的彩票玩法和创新的哈希算法,公平公正-方便快捷!哈希游戏官网,哈希游戏平台,哈希娱乐,哈希游戏前段时间想使用bee的热加载功能,就想着安装一下。安装的时候遇到了一点点问题,主要原因还是对golang不是很熟悉,非我的主要编程语言,偶尔自己想起来就用用,感觉半吊子都算不上。
然后做了些搜索,解决了问题,应该是没有启用GO111MODULE特性,我在goland ide里面启用了,但是go env里面缺没有设置。
今天在看丁奇老师的《MySQL实战45讲》时看到一个有趣的思考题,其实蛮考验对mysql知识的理解的。
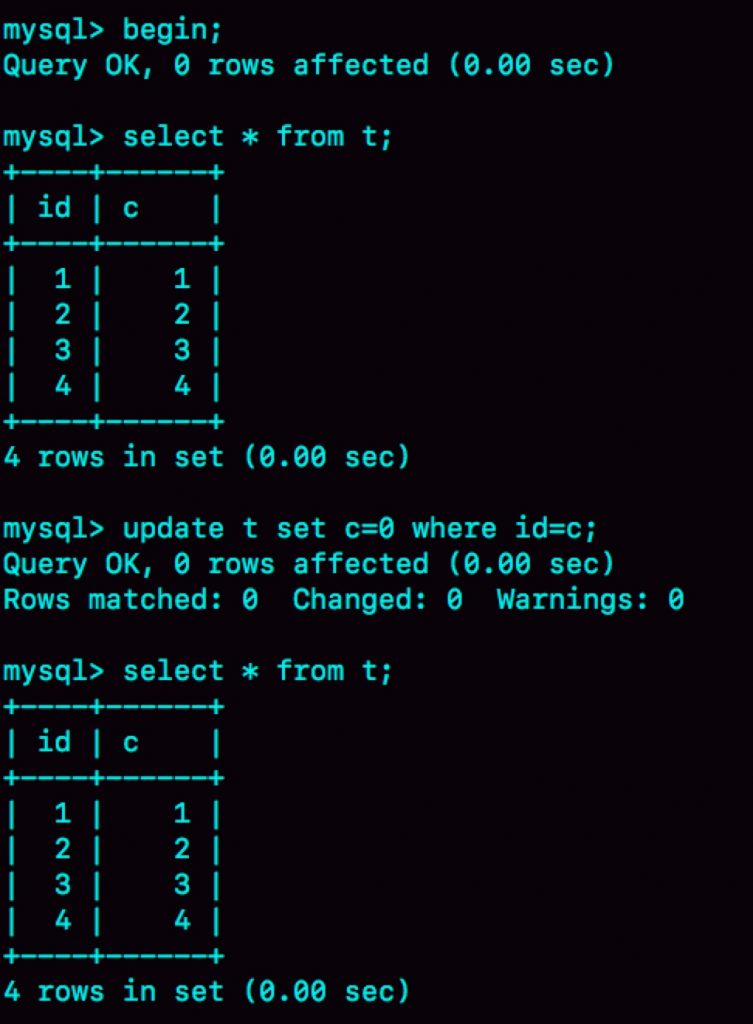
其实这道思考题主要考察了对mysql在RR级别下的可重复读和当前读。先来说一下答案,什么情况下会发生这种情况哪?另外1个事务对这4条sql语句做了修改,比如update t set c = c+1这种情况。当然update语句应该是发生在q1时刻之后的,不然select的结果就会是我们update之后的结果了啊。
这里主要考对mysql可重复读和当前读的理解。在事务中的q1阶段,select以后就创建了对t表的一致性视图,后面所有的操作都会是从这一时刻的一致性视图来读的。接下来其他事务修改了记录,可能表数据就如下了:
这里有一点要强调的是update语句属于当前读,而会更新当前的一致性视图(主要体现在将当前一致性视图相关的 up_limit_id修改为当前row的trx_id),不然如果其他事务有更新提交,就会被漏掉或者说覆盖了啊。因update t set c=0 where id=c没有有效的更新记录,如上图中“0 rows affected”,当前一致性视图也不会更新。因此下面的select语句又从一致性视图中读取到了相同的内容!
最近在开发一款小型游戏的服务端,目前基本完成开发了,就打算把它们部署到服务器上面。最终选择的方案是使用docker来完成,这个这过程中对我这个docker新人来说遇到了很多问题,当然也学习和成长了很多。今天来说的如何来保证docker中服务的启动顺序问题。
例如我现在有个和数据交互的db服务,依赖数据服务mysql_db。我使用docker工具是docker-compose,使用其中的depends_on来想解决问题。
是的,这样的配置可以保证db服务会在mysql_db服务启动以后再启动,一定程度来说如果mysql_db能立马完成启动,并准备好对外服务,那么就没有什么问题了。可是不得不面对的一个问题是,mysql_db启动是一个比较耗时的服务,当db服务启动时mysql_db其实还是在服务的启动过程中,并没有准备好来接受db的数据库连接,这样一来就导致了db服务的异常,进而导致所有依赖db服务都会异常。
docker-compose目前貌似并没有相应的配置参数来解决类似的问题,在google中找到了一个局限性的替代方案,使用entrypoint.sh脚本。在脚本中增加判断依赖服务是否已经准备完毕的判断,如果没有启动就一直等待,直到依赖服务启动以后,再启动脚本。他这里使用nc命令,对于没有nc命令的镜像就需要自己想办法来解决了。例如可以使用golang中的net.Dial来写个尝试连接的工具,当然其他语言类似的库也可以。
至此就可以明确保证我们db服务会在mysql_db准备好以后再来进行启动。
日志无论在开发还是生产当中,都是很重要的部分,帮助我们快速定位和发现问题。logrus是一个可以格式化存储日志的golang库,而且它还兼容标准库中的logger。logrus目前在github的start数量已经快达到10k,可谓是一个非常受欢迎的golang第三方库了。
完全兼容golang标准库日志模块:logrus拥有六种日志级别:debug、info、warn、error、fatal和panic,这是golang标准库日志模块的API的超集。如果您的项目使用标准库日志模块,完全可以以最低的代价迁移到logrus上。
可扩展的Hook机制:允许使用者通过hook的方式将日志分发到任意地方,如本地文件系统、标准输出、logstash、elasticsearch或者mq等,或者通过hook定义日志内容和格式等。
可选的日志输出格式:logrus内置了两种日志格式,JSONFormatter和TextFormatter,如果这两个格式不满足需求,可以自己动手实现接口Formatter,来定义自己的日志格式。
Field机制:logrus鼓励通过Field机制进行精细化的、结构化的日志记录,而不是通过冗长的消息来记录日志。
分隔日志使用了logrus提供的hook机制,然后利用rotatelogs实现这些功能。
周末的时候给网站做一个后台,前端用的是阿里的antd的angular版本。其中有用到他们的上传组件,由于有多个地方使用到上传,就把它封装成了一个通用图片上传组件。这时候服务端返回的图片链接地址,如何返回给父组件里面的表单里面哪?
这里贴了一下代码的实现,原理可以查看官方的相关文档。我写的时候也参考了《Angular:实现组件间双向数据绑定》。
一致性哈希也不是什么新东西,我第一次看到应该是2年前看《大型网站技术架构:核心原理与案例分析》的时候,不过除了面试的时候其他时候机会没有遇到过和一致性哈希相关的内容,然后慢慢的就是书的知识,我又还给了书。我有时候觉得有些知识不用代码敲出来,自己好像还是不会一样,所以今天就动手把别人一致性哈希golang的实现搬过来。在把代码复制拷贝一份,认认真真的看了以后,感觉一致性哈希也就这样(当然有空还是要好好补补高数)。
讲一致性哈希的资料很多,随便用google搜索一下,高质量的答案很多。我如果再说感觉意义也不是很大,如果你有幸读到这篇文章,我在结尾也会放一些相关的资料链接。
然后你会发现当你把虚拟节点设置的越大的时候,key的分布就会越平均,当值很小的时候分布的就很不均匀了。当然这也和我们测试的key的数量有关,我就放了这几个,如果你放的越多,它可能就越平均了。
冒泡排序应该是我们程序员接触的第一个算法了吧。前几天去面试,考了一下冒泡排序,长时间不用,只记得个大概,就是相邻的2个元素比较大小,然后互换,具体的记不清了。然后很紧张,就没写出来。今天趁着有时间就用代码敲了一遍,当做笔记。
这两天在考虑给我们4个人的小团队使用什么好的知识共享软件?第一个进入我的视野就是大名鼎鼎的confluence,无论从哪个角度考虑,confluence都是首选,而且我也装了,不过由于云服务器配置实在是太差,做一个操作就要卡上半天(cpu跑满了)。因此无奈,confluence被我pass掉了!接下来我考虑了一下Doku,这是一个php开发的小型wiki系统,其实它很不错,各方面都不错,而且插件也比较丰富。但是它有自己的一套语法系统,使用插件的话可以支持Markdown,但是相对比较麻烦一些,主要还是内心对它并不是特别喜欢吧,也被我pass掉了。最后进入我的视野的gollum(咕噜),这gollum和指环王中的是同一个词,不知道当初起名时,是不是作者比较喜欢电影中的咕噜。gollum是ruby开发的一套wiki系统,它支持Markdown语法、轻量级、结构清晰,看起来是不错的选择。
首先这里假设你已经成功安装docker了,如果你还没有安装,可以自行搜索一下资料,还是很简单的,这里就不再叙说了。
如果需要在线编辑,可以用nginx做一个反向代理,然后加一个http用户认证,当然权限部分就没办法了。如果不需要在线编辑,可以去掉gollum在线编辑功能,然后和类似jenkins集成工具整合,也是不错的选择。
最近看了原网易游戏引擎架构师蔡能老师一些游戏相关的文章,其中有提到在游戏中常用的脚本语言lua和C/C++之间相互调用。lua在游戏中有很多运用,耳熟能言的有《魔兽世界》,魔兽中UI和很多插件都是用lua来写。在服务端也有很多运用,nginx有支持lua语言的模块,具体可以看一下openresty这款阿里改写nginx服务器,它集成nginx lua模块,书籍可以翻阅《OpenResty-Best-Practices》。
在C\C++里面调用lua脚本通常有二种做法:一是读取后直接运行,调用luaL_dofile函数;还有一种方式是用luaL_loadfile函数将脚本压到栈顶,手动调用pcall运行脚本。
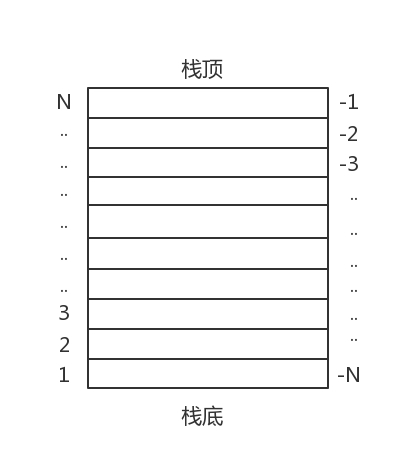
有时候我们会把需要运行效率的模块用C/C++来使用,然后封装以后交给lua来调用。这时候我们要用lua_register将函数注册到lua虚拟机里面,然后我们就可以在lua脚本里面调用这个函数了。lua_register是一个宏函数,如下:
第1个参数L是虚拟机指针,第2个参数是注册到虚拟中的函数名称,第3个参数是一个函数指针,格式为int ()(lua_State*) .下面我们来看一下具体的实现。
这些代码能运行的前提是你的电脑已经安装了lua,具体如果安装lua请自行搜索一下。
这里我提供一下我代码的示例,我用ide用的是clion。源码下载,use_lua.tar。
如果你是一个mac党,而且正在Alfred,那么这篇简短的文章应该可以帮到你。如果你是Alfred新手,还不清楚它是干什么的,那你最好去Alfred官网下载一个,然后自己动手试试,你可能就会爱上它。这里假设你是和我一样用过一段时间Alfred的菜鸟,希望它来帮助我们能来更好提高工作效率。那么Alfred提供的自定义搜索功能就不得不提了,欲知后事如何,请继续往下看哈!
那么我们就直奔主题,如何自定义搜索命令哪?我们先以google翻译的中英翻译为例来说一说吧!

我们想要使用web搜索功能,那么我们清楚网站提供什么样的web API给我们调用,这里面的google中英翻译的API大致是这样的,其中的{query}就是我们在通过Alfred搜索时提供的第二个参数,也就是我们搜索的内容了。具体的设置如下图:

来看看我们最终的劳动成果是什么样子的吧!按alt+空格(默认)激活Alfred,然后输入上面的Keyword中的命令,如果得到类似下面的结果,恭喜你!


